#
Technische Architektur
#
Plattform-Komponenten
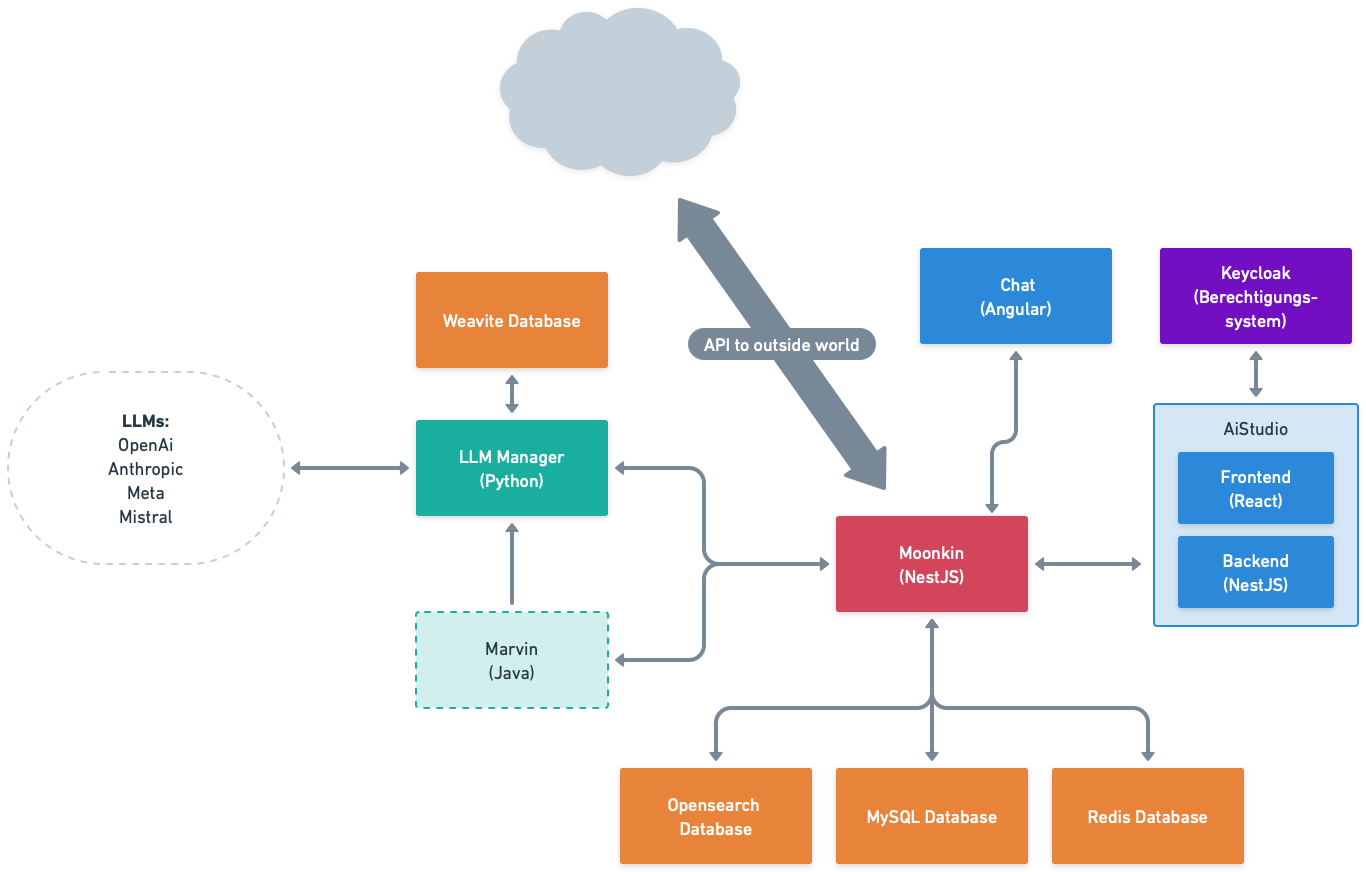
Die Architektur der Plattform setzt sich aus 7 Kernkomponenten und den zugehörigen Datenbanken für die Datenspeicherung zusammen.
#
Chat
Dient als Client für den*die Chatbotnutzer*in zur Kommunikation mit den Backend-Systemen. Die Verbindung findet dabei mittels HTTPS-Verbindung statt und nutzt die Dialog-API (JSON mit XML-Inhalten).
#
Editor (v5)
Ermöglicht den Editor-Nutzer*innen der Plattform die Verwaltung der Chatbot-Inhalte, sowie die Auswertung geführter Konversationen. Eine Authentifizierung des*der Administrator*in mittels Benutzername und Passwort ist erforderlich. Die Daten des Editors (Chatbot-Inhalte) werden dabei in einer MySQL-Datenbank gespeichert. Die Chatbot-Inhalte werden durch eine Editor-Schnittstelle zum Export angeboten (XML) und in die jeweiligen NLU-Instanzen (Marvin) überführt. Temporäre Authentifizierungsdaten (Session-Daten) werden vom Editor in einer Redis-Datenbank gespeichert. Der Zugriff auf die Konversationsdaten erfolgt per REST-Schnittstelle über die API (Moonkin).
#
aiStudio (Nachfolger des Editors, v6)
Ermöglicht den aiStudio-Nutzer*innen der Plattform die Verwaltung der Chatbot-Inhalte, sowie die Auswertung geführter Konversationen. Eine Authentifizierung des*der Administrator*in mittels Benutzername und Passwort ist erforderlich. Die Authentifizierung erfolgt über das Open-Source Identitäts- und Zugriffsmanagement Keycloak. Die Daten des aiStudios (Chatbot-Inhalte) werden dabei in einer MySQL-Datenbank und einer Weaviate-Datenbank gespeichert. Der Zugriff auf die Konversationsdaten erfolgt per REST-Schnittstelle über die API (Moonkin).
#
API (Moonkin)
Dient als Router / Koordinator für die anderen Plattform-Komponenten. Moonkin stellt eine HTTP-API (REST-ähnlich) zur Verfügung, welche von den anderen Komponenten genutzt werden. Die angebotenen APIs können zudem unabhängig genutzt und integriert werden. Hierfür steht die API-Dokumentation zur Verfügung. Die API-Schnittstelle verwaltet zudem den Status der NLU-Instanzen (Marvin). Die Speicherung temporärer Daten erfolgt in der Redis-Datenbank. Moonkin empfängt somit die Anfragen des Chats und leitet diese an die NLU-Instanz (Marvin) mittels HTTP-Anfrage weiter. Nach erfolgter Prozessierung wird das Ergebnis in der OpenSearch-Datenbank protokolliert und indexiert (Konversationsdaten). Die Daten der OpenSearch-Datenbank können mithilfe der Analytics-API abgefragt werden.
#
NLU (Marvin)
Bei klassischen NLU-Chatbots findet die linguistische Verarbeitung der Anfragen sowie die Erzeugung entsprechender Antworten über die NLU-Komponente Marvin statt. Je nach Anfrage können die Antworten dabei mit Informationen von Dritt-Systemen angereichert werden (s. NLU > Services). Bei Nutzung der Produktvariante Chat & Search werden Informationen bei der Bearbeitung der Anfrage zudem aus der OpenSearch-Datenbank bezogen. Bei KI-Assistenten wird Marvin für die Konversationssteuerung genutzt.
#
LLM Manager
Der LLM Manager ermöglicht die Integration von Wissen in das System, entweder durch den Import von Dateien oder das Crawlen von Websites. In beiden Fällen werden die Daten vektorisiert und in einer Vektordatenbank gespeichert. Eine weitere zentrale Aufgabe des LLM Managers ist es, die zugrundeliegenden Sprachmodelle mit relevanten Ergebnissen aus der Wissensdatenbank zu versorgen und so passende Antworten zu generieren ( Retrieval Augmented Generation (RAG) ). Es steht eine breite Palette an Sprachmodellen zur Verfügung, darunter Modelle von OpenAI wie GPT-4o, GPT-4o Mini und GPT-4 Turbo sowie Open-Source-Modelle wie Llama 3 und Claude 3.5.
#
Keycloak
Über das Open-Source Identitäts- und Zugriffsmanagement "Keycloak" werden Rollen & Rechte im aiStudio gemanaged.
#
Ventrikel
Bei Einsatz von Chat & Search ist die kontinuierliche Anlieferung von Daten an die OpenSearch-Datenbank notwendig. Diese verwaltet und indexiert die durchsurchbaren Dokumente (Dokument beschreibt hierbei einen technischen Datensatz). Die technische Anlieferung und kontinuierliche Aktualisierung der Dokumente übernimmt die Komponente Ventrikel. Sie übernimmt die Aggregation von Informationen aus Drittsystemen (wie Confluence oder ServiceNow) und liefert diese an die OpenSearch-Datenbank an (HTTP-API mit JSON als Datenformat).