#
Datenbasis erstellen
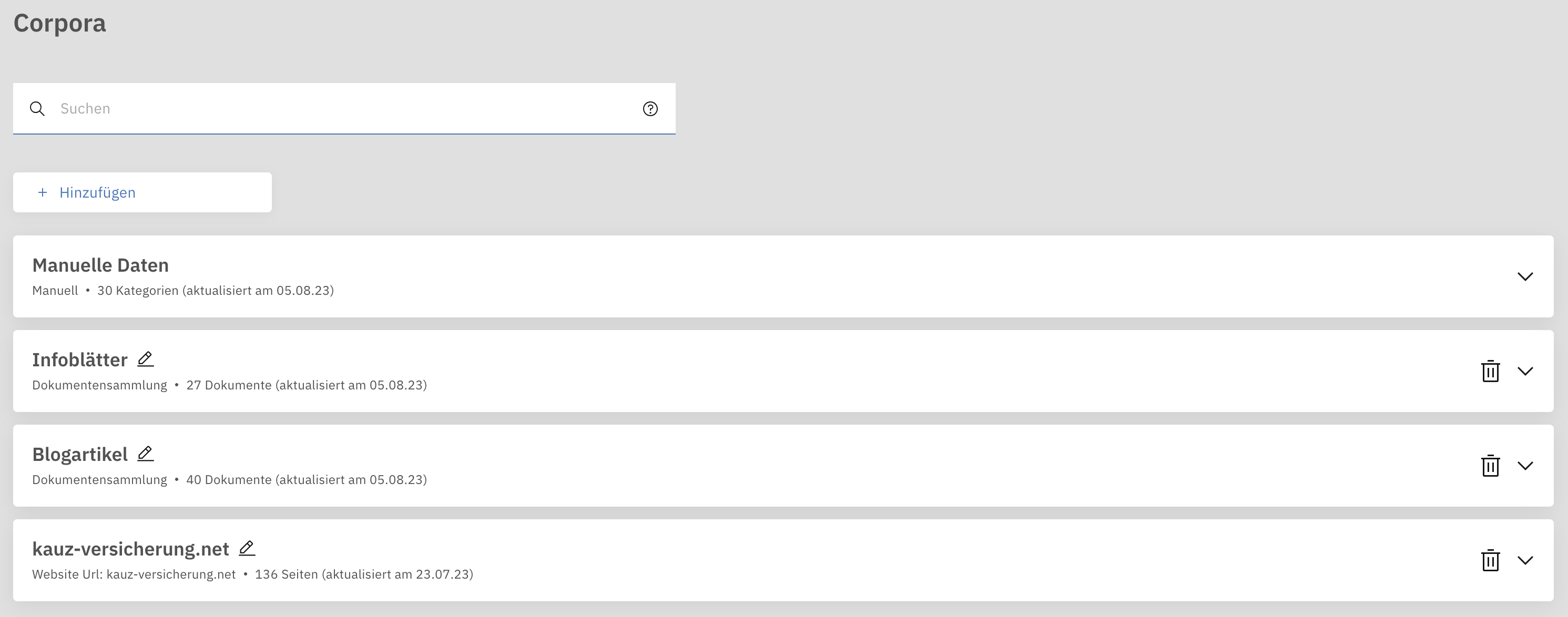
Über den Menüpunkt ChatGPT-Integration gelangen Sie zu einem Überblick über die aktuellen Korpora.
Ein Korpus kann aus mehreren Dokumenten bestehen. Bei einer Website sind dies die einzelnen Unterseiten, bei einer PDF-Sammlung sind dies die einzelnen PDF-Dokumente. Ein Dokument wiederum besteht aus vielen Chunks. Dies sind die beim Crawling identifizierten und extrahierten Textabschnitte, für die Embeddings berechnet werden und die für die Beantwortung von Fragen herangezogen werden. In der Übersicht ist für jedes Korpus angegeben, wie viele Dokumente es enthält und für jedes Dokument wiederum angegeben, wie viele Einträge (also Chunks) es enthält.
Wenn noch keine Daten vorliegen, die als Datenbasis für die ChatGPT-Integration genutzt werden sollen, sehen Sie zunächst nur eine Möglichkeit zum Hinzufügen von Datenquellen.

#
Datenquelle bestimmen
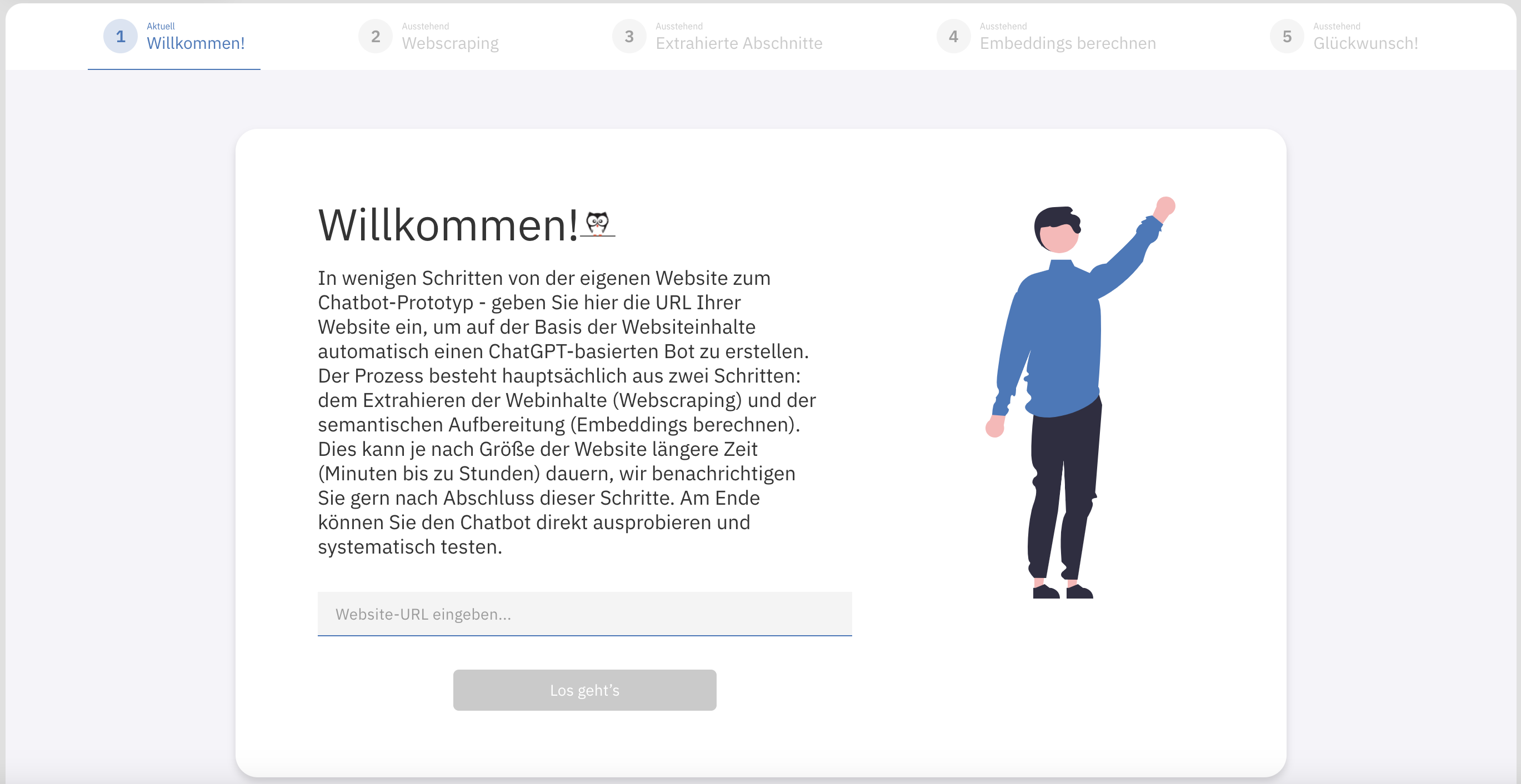
Mit Klick auf Neue Datenquelle einlesen bzw. + Hinzufügen (wenn schon Korpora vorhanden sind) starten Sie den Prozess zur Aufbereitung der Daten. Im ersten Schritt können Sie die von Ihnen gewünschte Website-URL angeben oder per Drag & Drop Dokumente hochladen und mit Klick auf Los geht's das Webscraping bzw. das Dokumentenparsing starten.
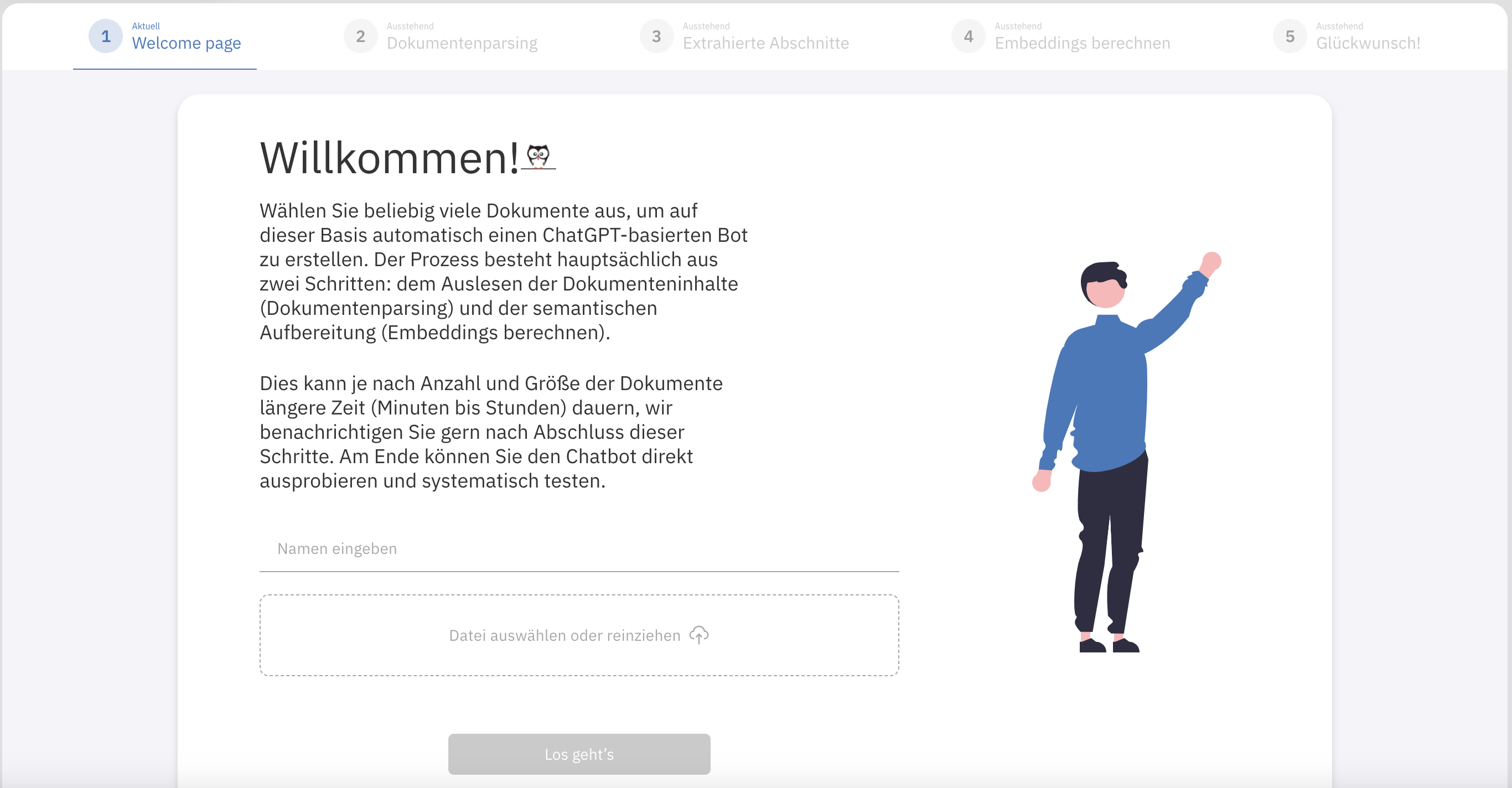
Aktuell können die folgenden Dateiformate geparsed werden: pdf, odt, txt, docx, xlsx, csv, eml, pptx
#
Webscraping bzw. Dokumentenparsing
Beim Webscraping bzw. Dokumentenparsing werden die Inhalte einer Website bzw. eines Dokuments extrahiert. Bei einer Website werden alle Seiten gecrawled, die unter der angegebenen "Seed-URL" zu finden sind. Da das Webscraping bzw. Dokumentenparsing abhängig von der Größe der Website bzw. des Dokuments einige Minuten bis zu wenige Stunden dauern kann, können Sie sich per E-Mail benachrichtigen lassen, wenn der Vorgang abgeschlossen ist.
#
Extrahierte Abschnitte
Im folgenden Schritt können Sie sich die extrahierten Abschnitte ansehen. Auf der linken Seite finden Sie einen Überblick über die einzelnen Dokumente, in diesem Fall also die Unterseiten der gecrawlten Website. Möchten Sie eins der Dokumente nicht in Ihre Datenbasis aufnehmen, können Sie dies mit Klick auf Löschen (oben rechts) löschen.
Wenn Sie eins der Dokumente auswählen, werden auf der rechten Seite die einzelnen extrahierten Abschnitte angezeigt. Prinzipiell werden Abschnitte, die 20 Token (~ 80 Zeichen) oder kürzer sind, ignoriert. Mit Hilfe des Filters Ignorierte Einträge anzeigen können Sie diese anzeigen lassen. Außerdem haben Sie die Möglichkeit die Einträge zu durchsuchen und können weitere Einträge ergänzen.
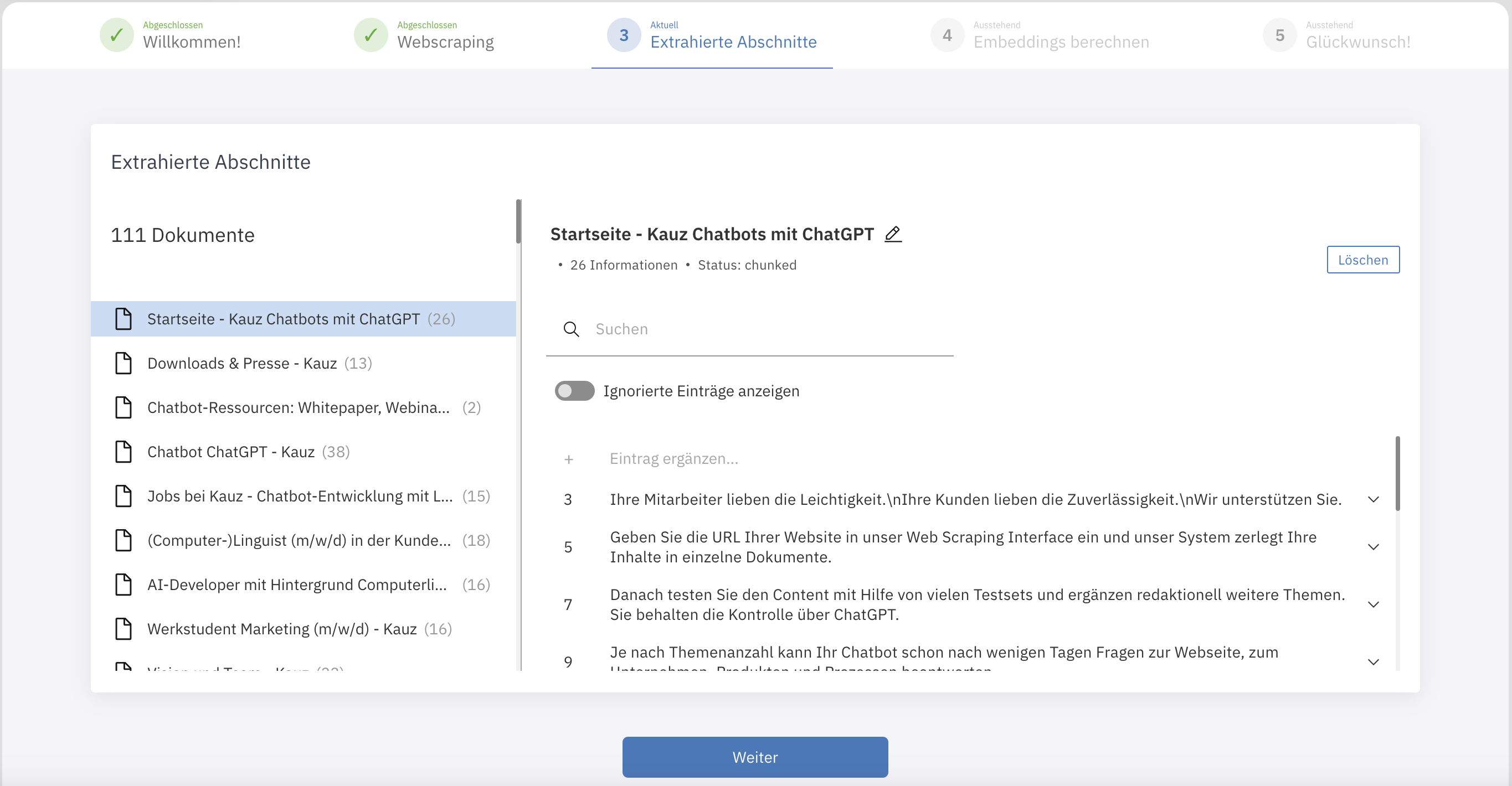
Mit Klick auf einen einzelnen Eintrag erhalten Sie die Möglichkeit diesen zu ignorieren, zu bearbeiten oder zu löschen. Eine Bearbeitung der Einträge ist auch zu jedem späteren Zeitpunkt noch möglich ( Daten bearbeiten ).
#
Embeddings berechnen
Im nächsten Schritt werden die Embeddings, also die Ähnlichkeiten zwischen verschiedenen Textabschnitten, berechnet.
#
Erste Tests
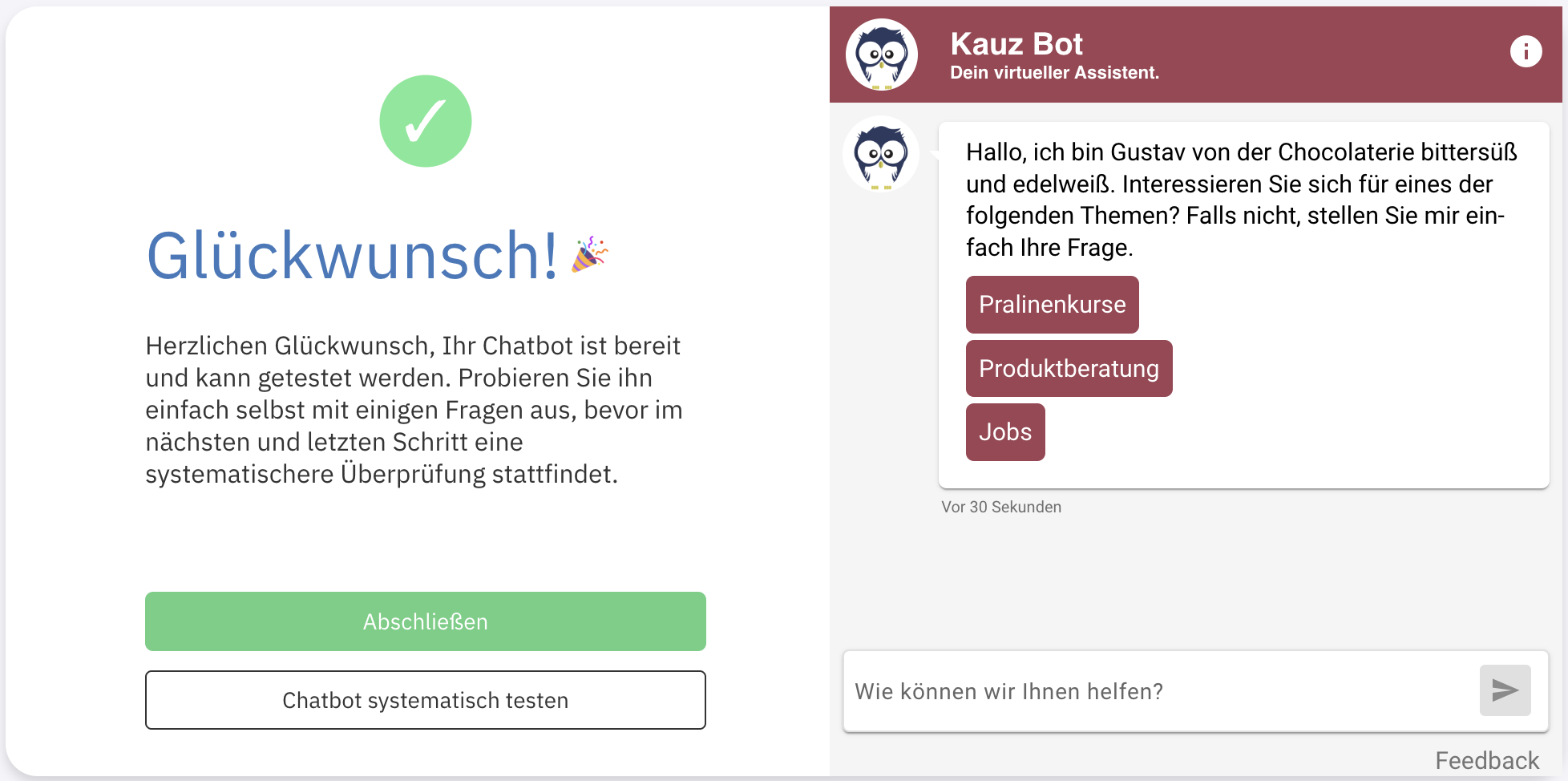
Nach Abschluss der Berechnung können Sie Ihren Chatbot bereits zum ersten Mal testen. Über den Button Chatbot systematisch testen gelangen Sie zur Testseite. Dort können Sie systematische Tests durchführen und Testreports generieren lassen.